Correcting for Quality
27th of March 2016Data Quality Management is the approach for making and keeping data in a state of completeness, validity, consistency, timeliness, integrity and accuracy. In order to profile and assess data for these qualities so that this information can be passed on to data cleansing services, rules in accordance to the data policies of an organization are applied. These rules come in a wide variety of functionalities attuned to the business logic and lexicon of the organization that utilizes them, and are more often than not specific to said organization. Examples of such rules are uniqueness rules or validation rules (such as minimum and maximum length checks) and mandatory fields.
Quoting the SAS party line: Data Quality Management entails the establishment and deployment of roles, responsibilities, policies, and procedures concerning the acquisition, maintenance, dissemination, and disposition of data. A partnership between the business and technology groups is essential for any data quality management effort to succeed. The business areas are responsible for establishing the business rules that govern the data and are ultimately responsible for verifying the data quality. The Information Technology (IT) group is responsible for establishing and managing the overall environment – architecture, technical facilities, systems, and databases – that acquire, maintain, disseminate, and dispose of the electronic data assets of the organization.
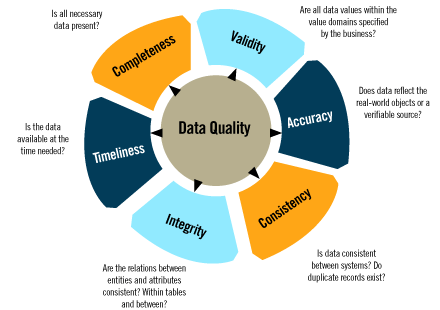
Since data quality management is situated on an enterprise scope, it faces many of the same problems other such disciplines face. Where the need for data quality management is concerned , most of the common pit traps have a familiar ring:
- No business unit or department feels it is responsible for the problem.
- It requires cross-functional cooperation.
- It requires the organization to recognize that it has significant problems.
- It requires discipline.
- It requires an investment of financial and human resources.
- It is perceived to be extremely manpower-intensive.
- The return on investment is often difficult to quantify.
Data cleansing services employ a variety of automated techniques in order to rectify the issues detected in the profile and assessment actions. Foremost, the services should scrub the data by correcting data errors. As an example, data entry errors will cause repositories to contain misspelt words or incorrect values. The steps taken to cleanse the data can then be incorporated in data standardization, imposing restrictions on data entry, such as text structures, date format structures or value structures (enumerations). Data matching and merging services detect similar data that are duplicates with small differences, and perform a de-duplication so that the best-fit record is defined and referred to by this clones. This is where data enrichment can also play a part. Data enrichment adds additional values and metadata tags to existing data in a controlled manner in order to prevent manual (and thus error prone) augmentation. Data remediation (or harmonization) is the ability to push cleansed data in the data warehouses back into the original sources that provided the data. While this should be strived for, it might not always be possible, as source system restrictions might inhibit it.
Evidently, not all data quality issues can be handled in an automated way. Sometimes, manual intervention is needed, as a human resource can more easily detect context and interpret natural language. A capability that supports the needed actions can be foreseen so that data errors can be fixed, ignored, quarantined, or labeled as dirty based on individual situations.
These techniques can be utilized as part of a data quality management process, going from Assessment to Monitoring. This is a process of continuous improvement, utilizing metrics to achieve ever cleaner data&, much like Six Sigma in the world of Business Process Management. These metrics should be visualized in a monitoring approach (such as a management dashboard), so that the proper “next steps” can be determined.
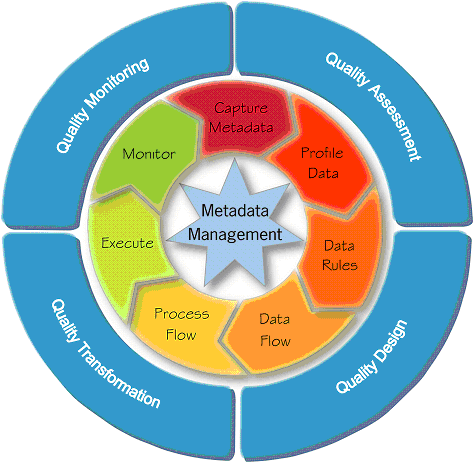
Phases of Data Quality Management (Oracle)
| Thought | EIM |