Tying It All Together5th of October 2017There is no denying that the Micro Services architectural paradigm has had an impact on the current IT development landscape. Whether you consider it to be a refining of the classic Thomas Erl-style SOA or something completely new, the fact of the matter is that it is here to stay for the foreseeable future. However, this does not mean we need to blindly follow the tenets of its faith. There are always considerations to move from its core to a more hybrid form of architecture. Because, as with any architectural style, the choice for Micro Services has both benefits and ramifications for the enterprise that employs it. Think of the difficulties that arise with Micro Services for actions that span large parts or even the entire business process, as discussed earlier. As I see it, the independence of each service and the choice for choreography over orchestration in most Micro Services architectures is where the lion share of the ramifications spring from. It delivers much of the benefits promised by Micro Services, but at the same time decouples most of the coherence of the business processes in execution. And with all architectural choices, a balance between these benefits and ramifications is at the core of the architect’s or designer’s job. But for this article, let’s consider this choice for choreography at bit. |

|
The Netflix Open Source Software (OSS) framework is one of the leading Java frameworks when it comes to the Micro Services paradigm. Traditionally, these types of frameworks tackle automating business processes implicitly as a combination of pub/sub services , with an optional system similar to the Google Dapper approach. However, near the end of 2016 it realized that for complex processes, this becomes impractical, and the visibility it allows on distributed workflows is cumbersome without a central orchestrator. Another consequence is that determining what the remaining tasks are for a process, becomes similarly difficult in a setup where the code making up the process is scattered over several applications and services.
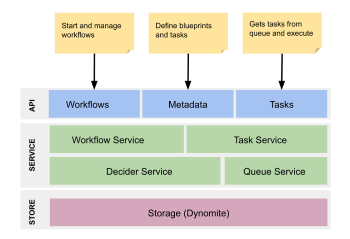
For this reason, they developed Conductor, an orchestration engine to be used in concert with their services. Its capabilities are straightforward:
- Tracking and management of workflows, with the ability to start, pause and stop them.
- A user interface to visualize these processes.
- Its “blueprint” (a context that is passed along with each transaction in the workflow in order to manage the state) and an underlying queueing mechanism.
- Scalable to millions of concurrently running process flows (I am trusting their documentation for this, as I have not tried it out on such a large volume).
- Support for multiple protocols (HTTP, RPC, …)

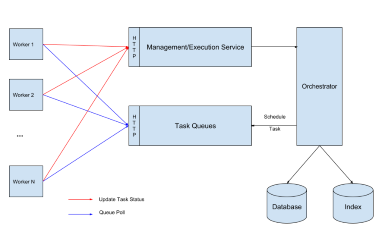
It would seem the need for a distributed system that is not centrally orchestrated, stems from the fact that most BPMS solutions aren’t geared for performance when dealing with large volumes. The main argument for this is that these systems are all about long running tasks, wand that these don’t have those microsecond requirements for speed. I am glad to see that there are vendors out there that have realized this “weakness” in their product and are actively trying to fix this. I am thinking for example of the TNG initiative at Camunda.
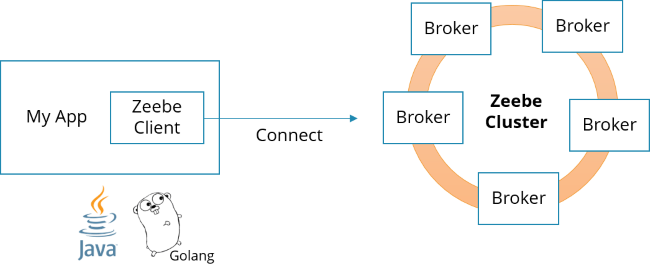
Speaking of Camunda, August 2017 they released their proper implementation of a Micro Services orchestrator, which they christened Zeebe. In short, it allows for a publish/subscribe mechanism for services to become part of a process flow, visualized using BPMN, making sure all service interactions described in the process are enforced. The services work on a client/server basis with the orchestrator through a Zeebe client incorporated into the service implementation, as shown on the diagram below.

If there is a need for following up the business process, but a central orchestrator is out of the question, this can still be done by analyzing the individual steps of the implicit process. We would need to log these steps for them to be correlated. The aforementioned Google Dapper is an abstract that states a solution for distributed tracing. Implementations such as Spring Cloud Sleuth, Zipkin or Apache HTrace also provide the functionality to be able to do this.
In effect, this approach could be likened to a perpetual sort of Process Mining based on the trace logs generated by such a framework. As such, they need to follow the guidelines to be prepped for such a mining effort. In essence, they need to log the following parameters for each implicit step:
- The Business Process Context: A unique identifier with which we can correlate all activities part of the same process instance.
- The Process Step: A unique identifier for indicating which activity in the process has been logged. This could be the service name or operation being triggered.
- The Activity Timestamp: A time indication of when (and preferably how long) this activity took place.
- Optionally: A host of additional information, such as the performer identification and/or role, adds to the options we have for analyzing the process.
| Thought | BPM | SOA |