If At First You Don't Succeed...
3rd of January 2017Back in the day when arcade machines with coin slots were still a thing, the only cost and only operation needed to continue after failing a task (like save the princess) was to insert a coin of the appropriate value. The arcade halls belong to the days of yore now, at least in Belgium, but their image got stuck in my mind when I was pondering the need to retry failed tasks in business processes. Surely here the cost to retry saving the princess or any other task is a bit higher than slotting another euro piece.
Prompting this trip down memory lane was a design by one of my team members for an automated business process in IBM Process Manager. The purpose of the business process is rather simple. At a certain time a request is launched to an external web service and depending on the answer certain human tasks need to be executed. However, how to deal with the possibility that the service call returns an error such as for example the remote service is down? It is clear that this service call needs to be retried in order to proceed to the needed human tasks. The policy of the architecture in place stated that this retry needs to happen up to three times (each time with a waiting time increment of a few seconds) before letting the process go in an error state and having someone from operations take a look at why the service call is failing.

At the descriptive process level the retry isn’t considered, and one could argue that even the analytical level should worry too much about this phenomenon, but at the executable level there are decisions to be made. The first attempt of my designer was to explicitly model the retry as an escalation of the service task (Request Customer Information), resulting in a model as shown in the illustration below. The Retry Customer Request is a subprocess which contains logic that based on the number of the iteration a wait is executed and then within the subprocess the Request Customer Information service is called again.
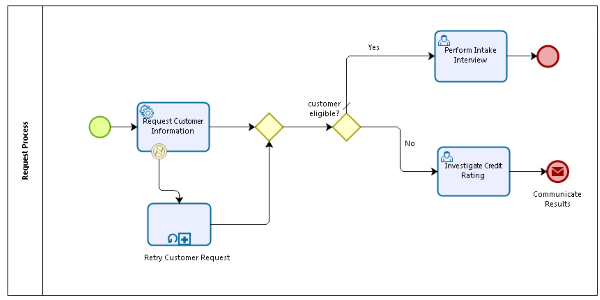
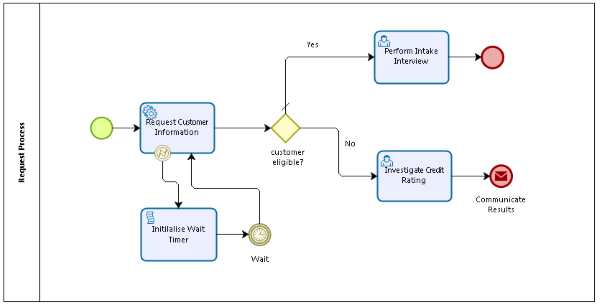
This is a horrendous approach to the retry problem. Not only is the service call relaunched in a different process model, but at the very least the first call to the service should be included in this subprocess. Using a timer event and a script task to set the proper time based on a process variable is at least a cleaner way to tackle the retry issue. Everything is then in the same process model and can be more easily understood when looking at the model. Not to make the model too convoluted I’m making abstraction of the fact that we still need a boundary rule checking whether or not another retry is needed. This could be done by introducing a gateway right before the script task.
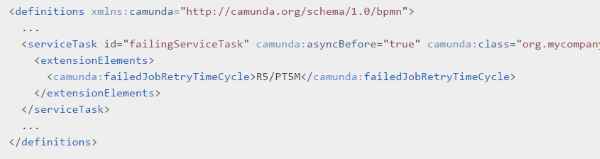
But one should put the question up whether or not this retry mechanism should even show up in the model at all. We could hide this retry mechanism behind the service implementation. Or we could make use of some of the features of the BPMS engine we are employing to automate the process. For example, the Camunda BPMS has a property on the service task called “failedJobRetryTimeCycle” which allows for the retry mechanism to be configured with a wait time in between.
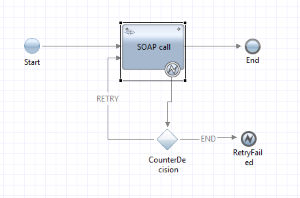
In our case, we employ the IBM Process Manager which has a feature for implementing the behavior of a service task using the integration designer. This way we also avoid polluting our BPMN model with these types of useful but very technical information. An example integration flow is shown on the right, and for this we even applied pre- and post-execution assignments in the properties of the designer to model the wait timer using a process instance variable. In this example the first retry will wait for 0 seconds, the second for 10 seconds, the third for 20 seconds and so on, determined by the counter being augmented before the SOAP call.

I very much prefer this approach to keep the retry mechanism out of the business process model. The only notable exception to this approach would be if the number of executions were somehow relevant to the execution of the process, for example in a monitoring schema for the Business Activity Monitor. But even in such more unusual cases, I will still probably look for an alternative to the business need for knowing the number of executions than to add it to the model.
One caveat is that implementing a sleep command into your retry code might compromise the performance of your engine, as the command occupies a thread while waiting. This means that if too many retries happen at the same time, the thread pool is emptied, and the engine stagnates waiting for the resolution of the retrying services. This is why configuration of a thread pool manager, such as the Work Managers in the IBM Process Manager, needs to happen to support the mechanism.
| Thought | BPM | SOA |