Reading between the Lines
23rd of November 2015For too long in my career have I obsessed about processes, and made abstraction of the data driving these processes. So, I’ve set on the path of discovering what the data is all about, and I’m chronicling my journey in the lines you are gazing upon. The need for information management should be clear. In a world where the amount of data rises exponentially on a daily basis, and it getting more and more complex, information competes for the time of its consumer which remains constant at 24 hours a day. Under the umbrella of the Enterprise Information Management discipline, I’ll look into the architecture principles that can help out an organization in achieving its strategic aspirations. But first things first: definition time!
What is Enterprise Information Management? Plainly put, it is a discipline to aid organizations in getting optimal use out of the data available to it. Also known as Enterprise Content Management (ECM), over the last decades, several disciplines have merged into this one unifying approach. Disciplines such as Electronic Document Management (EDM), Web Content Management (WCM), Master Data Management (MDM), and Business Intelligence (BI) have been compressed into a strategy used by organisation performs in its data analytics endeavors, be they big or otherwise. Wikipedia even throws Business Process Management and Customer Experience Management into the mix. Myself, I would not go so far as to add these two. This discipline, and the subsequent strategy the organization takes in it, is a critical tool in keeping pace with the expansive growth of available data within and outside of the organisation’s boundaries, providing a framework for governance and integrity of data and content.
The need for such a discipline is a matter of evidence in a lot of organizations. Over the years, they tend to accumulate several operational systems with divergent data and operational needs. Where at first they tend to align with the boundaries of said systems, over time, a series of challenges creep to the front stage identifying the need to leverage them outside of these boundaries. The pitfalls of data replication or point-to-point integration loom around the corner, and before anyone realizes it, a costly project needs to streamline these data source into a coherent picture. A single version of the truth.
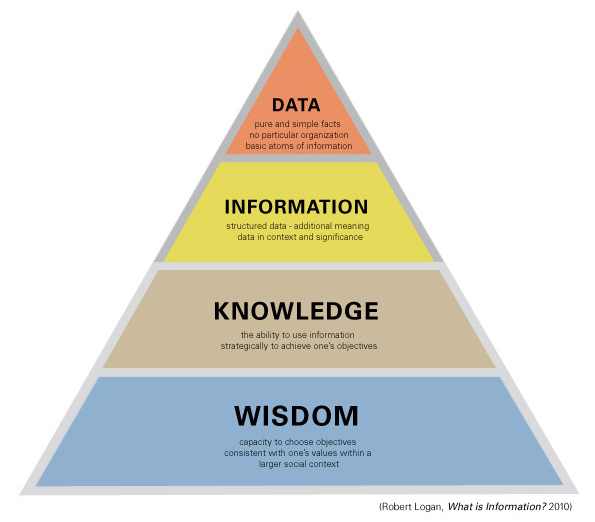
EIM helps you get a handle on data, but has the word "information" in its title. It is important to realize, there is a difference between the two, as stated in Robert K. Logan’s seminal work "What is Information?" Data is a representation of facts, pure and simple. It has the tendency to lack any context or relationships outside the operational system where it is found, and thus can be considered raw and unorganized. It might even be in a format that renders it resistant to effort in structuring it.
Information on the other hand is quality data that has been organized within a context of increased understanding and timely access. Peter Drucker states this as "Information is data endowed with relevance and purpose". Knowledge takes this information, and links them to the strategic vision of the organization. It is the insight into this information, and the intelligence that can be gleaned from its consumption and exploration. It is information, rendered actionable. It lends itself to act upon it in an informed manner, and fully conscious of its context.
The final evolution of data would be to result in wisdom. Wisdom is applied knowledge, deriving a hidden truth behind the knowledge to form a new corporate strategy or paradigm. This is where predictive analytics can be taken to shape the reality of the organization, or to align it with the reality of the community or industry it is situated in. As with all maturity levels, this is a plateau only a select number of organizations will ever reach.
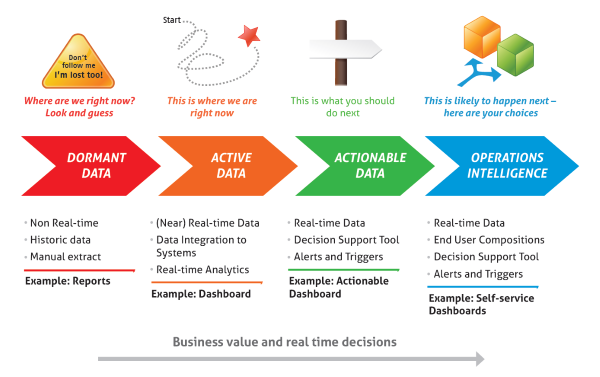
The illustration below is a diagram used by OpenText to illustrate these levels of maturity and their application in an organization.
No matter the level of maturity of the data, we need to store them in logical units. These units are called data repositories (or databases in the broadest possible sense). Data repositories can be categorized per repository structure or the medium on which they operate.
Looking at the structure, data persistence happens mostly in relational databases nowadays. Relational databases are the de facto-standard due to their catering to a very broad range of users and their use of SQL. The two-dimensional structure of the store in the form of tables, and their storage and retrieval operations are well known, mature, and heavily supported by frameworks and tools. If we move to a multi-dimensional structure, we speak of data cubes. These cubes consist of cells, each of which contains aggregated data related to their data’s dimensions. This enables high performance, making it a staple for online analytical processing (OLAP).
Then there are the NoSQL databases, which is a denomination of special purpose non-relational databases. Typically, a NoSQL database lacks predefined schemas so that the data model can evolve over time without the need for restructuring. There are many flavors of this type of database, of which the most know are the following: Key-Values Databases, Columnar Databases, Document Databases and Graph Databases. The difference between these flavors, and how to decide which is needed, deserves a few thoughts of its own.
| Thought | EIM |