Little Drops in Big Ponds
8th of December 2015In a previous article, I delved into the different types of data, and the different types of repositories this data can be stored in. I also specified the different flavors of a NoSQL database, but did not elaborate on any of them. This lack of depth shall be remedied in this article.
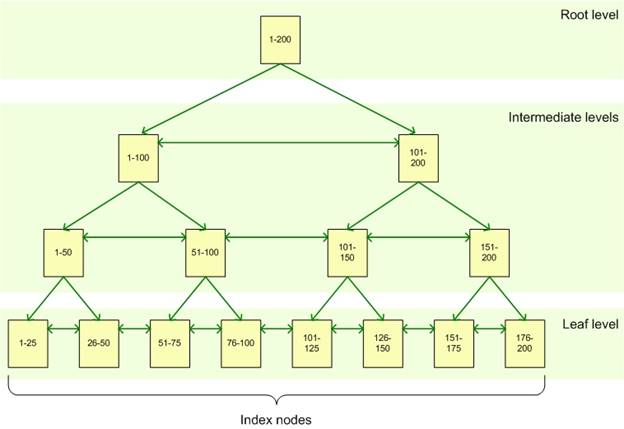
Key-Value Stores consists (as its name indicates) of simple records based on two values, namely a key and a value. These records are typically indexed in a B-Tree structure, as shown in the example below. This approach offers the flexibility to store almost any data structure, leaving the interpretation of the value field to the components reading or manipulating the data (lack of schema). However, the delegation of the context makes it difficult to update only part of the value, or to query the data in different ways. Value fields tend only to be queryable through their assigned keys, offering lightning fast lookups in this manner. Data structured in this way best suits uses as dictionaries, collections (such as for example a shopping cart), logging, etc… A little sidebar: The B-Tree structure is not the only tree structure for indexing that can be employed. For a more indepth look at other possible structures, each with their proper benefits and consequences, navigate to this thought.
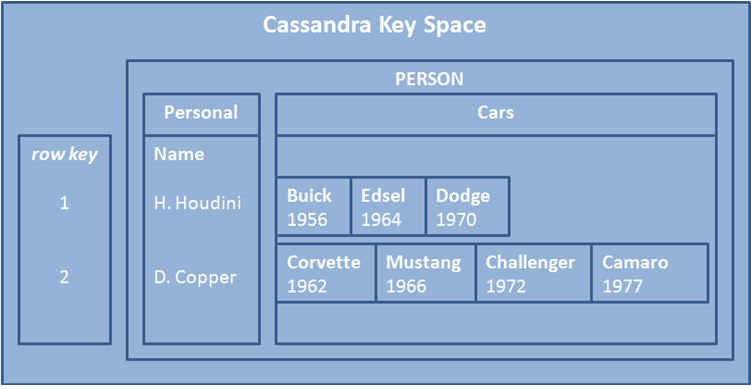
Columnar Family Stores are repositories designed to read and manipulate groups of columns and records. These records are grouped together in families, which typically share a physical location (for example the same disc), although the complete collection of families is normally distributed over several discs. As these databases store columns on the same blocks within the database instead of grouping records in blocks. This adds the benefit of not needing to fetch an entire record, thus not needing to disregard unneeded data. This translates into being efficient for data that needs to access a subset of columns in groups of records. This enables fast lookups and a good distribution of data. The drawback is a very low-level API.
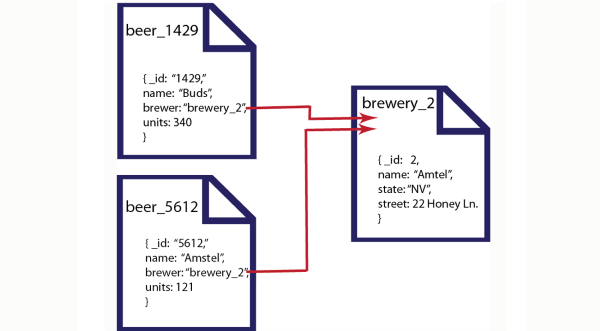
Document Databases are aimed at the storage of document-oriented self-describing data structures (such as XML or JSON). Documents boil down to an expanded key-value store where each value is once again a key-value, nested as far down as needed. This structure allows great latitudes for incomplete data, and is better at supporting queries, which however cannot be done using standard query syntax, nor are they as performing. This structure lends itself perfectly to such functional needs as content management, session management, profile data and the like.
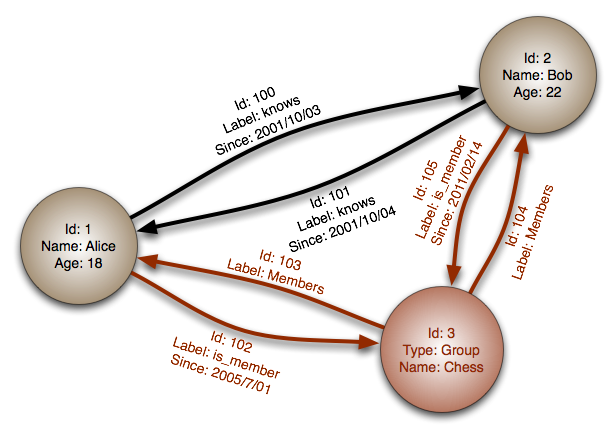
The final flavor is a graph database. Rows and columns are replaced by a flexible graph model to manage objects (or nodes) and the relationships (or edges) between them, as well as an arbitrary amount of attributes on each object (as a key-value pair). Querying is data-model specific, and its graph nature is exists mainly in the data layer of the consuming component. Its strengths come from implementation of graph algorithms such as shortest path or n-degree relationship. However, this does mean that to achieve definite answers, an entire graph might need to be traversed. Typically, this repository is used for social relationships, public transport links, and network topologies.
In summary, an overview of these flavors can be found in the table below:
| Datamodel | Performance | Scalability | Flexibility | Complexity | Functionality |
| Key-value store | High | High | High | None | Variable (None) |
| Column Store | High | High | Moderate | Low | Minimal |
| Document Store | High | Variable (High) | High | Low | Variable (Low) |
| Graph Database | Variable | Variable | High | High | Graph Theory |
As an addendum, choosing between using a standard RDBMS or a NoSql DB can be drawn up as such:
| NoSQL |
|
| RDBMS |
|
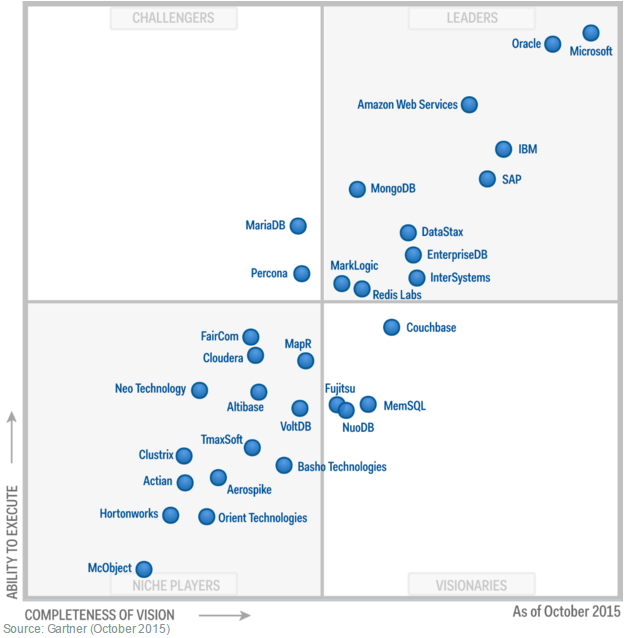
When determining which technologies are best suited for each of these flavors, I provide here the Gartner Magic Quadrant of October 2015 for Operational Database Management Systems. The complete report can be viewed as a courtesy of MongoDB on their site.
The next thought will address the outside factors on EIM, as well as how to go about an efficient governance of the data.
| Thought | EIM |