Swimming in the Water
6th of April 2016In a previous thought, I considered the Five-Layered Business Intelligence Architecture of IBIMA, and in my exploration of its Data Warehouse Layer, glossed over the Operational Data Source, Data Warehouse and Data Mart repositories. In this thought, I add the Data Lake to the mix.
A data lake is a large storage repository in which massive amounts of raw data are stored in their native format. The main benefit of such a construction is the centralization of content away from their respective silos, so that they can be combined and processed using search functionalities (such as Cloudera Search of Elasticsearch) and analytical capabilities, which would otherwise not be possible. Once transferred into a data lake, data can be normalized and enriched (through for example metadata extraction or aggregation). This data is prepared as needed (real-time), reducing the need and cost of up-front processing.
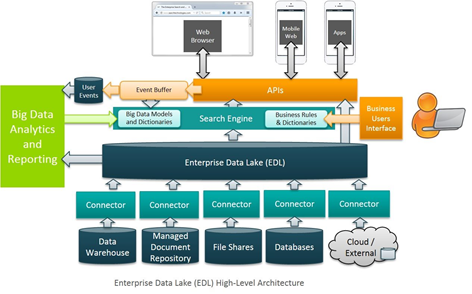
The diagram above suggest a possible high-level architecture for an Enterprise Data Lake, as posted on the website of Search Technologies. However, since the Data Lake is a relatively new concept, future developments might include such components as content processing via a business user interface, text mining, document management integration, enterprise-scope schema management…
While it does seem to fulfill a similar purpose as the classical Data Warehouse, this is only an illusion. Both repository types are complementary to each other and fulfil a specific function within an organization. Where Data Warehouses are geared towards use by the business owners and are aware of context, Data Lakes are to be utilized by specialized data scientists in data analysis. And as such, they are optimized for this purpose. Another main difference lies with storing the data. Before data can be loaded into a data warehouse, there is a need to structure it into a structure defined at design time. This is called schema-on-write. With a data lake, raw data is stored in its native format, as-is, and then when the need arises to produce the data for a particular consumer, it is given shape and structure. That’s called schema-on-read.
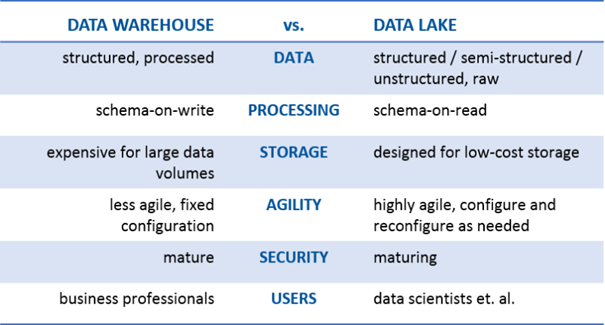
Some other differences between the two can be found in the table below:
Nevertheless, a Data Lake does come with some non-negligible downsides and risks, of which the most important ones are these:
- The inability to determine data quality.
- Reduced visibility on findings of other analysts on the same datasets (could be mitigated using descriptive metadata or other mechanisms).
- Security and Access Control: Still in its embryonic stages. For example: Data can be put into the Data Lake without oversight, causing regulatory and privacy issues.
- Performance is also an important aspect. Tools and data interfaces will not perform at the same speeds as working with repositories structured for their specific purpose.
- A Data Lake assumes that users recognize or understand the contextual bias of how data is captured, that they know how to merge and reconcile different data sources without 'a priori knowledge' and that they understand the incomplete nature of datasets, regardless of structure.
| Thought | EIM |