Intelligent Data Design
24th of March 2016In a previous thought, I quickly listed the different types of data repositories, based on their designated purpose. However, to illustrate how these different repositories click into one architecture, I propose to look at the Five-Layered Business Intelligence Architecture of the International Business Information Management Association (IBIMA). IBIMA is an academic association dedicated to promote the careful examination and dissemination of modern management and Business solutions in today's business environment and to bridge the gap between research and practice. A model of this architecture can be seen below. With this though, I will only go into detail about the Data Warehouse Layer and the ETL Layer. The remaining layers will be considered in other articles.
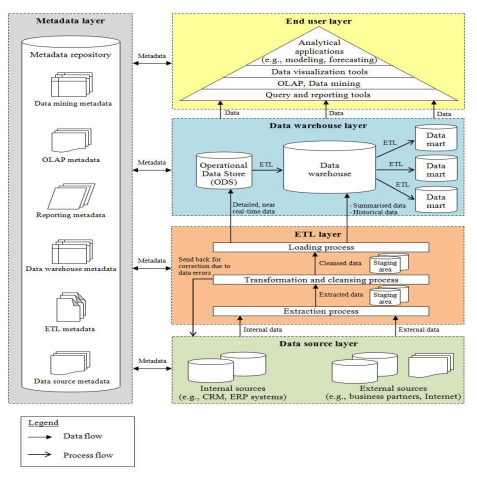
The ETL Layer focuses on three processes: extraction, transformation and loading. The extraction of the data from the sources and the subsequent transformation and cleansing of the data happens in stages, and each of the intermediate states of the data are stored temporarily on staging areas designed for this purpose. Transformation processes will typically consist of conversions using sets of business rules (such as for example aggregation) to create consistent views for reporting and analysis. The mappings of data types and standardization of data are also business logic to be take care of during the transformation of data. The cleansing process consists of data error identification and correction (or return to original data source for correction) through predefined rules.
The Data Warehouse Layer is where we see the use of the repository types. Operational data stores (ODS), data warehouses and data marts, together with the respective data flows between them, make up this layer.
The purpose of the ODS in this architecture is to integrate all data loaded by the ETL Layer, and load them into the data warehouses. It stores subject-oriented, detailed and current data from a wide variety of sources so that tactical decisions can be made in an informed manner, based on near-realtime data. As such the ODS is volatile, not containing any historical data, but is designed to support operational processing and reporting needs of a specific component.
Data Warehouses are a centralized collection of data in support of management decision making and analytical processes. They are defined by the following characteristics:
- Subject-oriented: data is grouped based on common subject areas that merit an organization’s focus (for example customers, sales, products…).
- Integrated: data is gathered in data warehouses from different sources in a consistent way.
- Time-Variant: The data stored has a time dimension in order to track trends and changes within said data (in other words: the historical changes of each piece of data).
- Non-volatile: New data is regularly added, but all data is read-only. No updates or deletes of data are allowed by users.
Where data warehouses are mainly used to support needs across the entire organization, the data marts will cover the needs for specific departments or domains. They are a subset of the data warehouse from which they derive their data, but still with a historical change perspective intact. However, this historical perspective is usually limited to a set number of days in the past (typically 2 to 3 months).
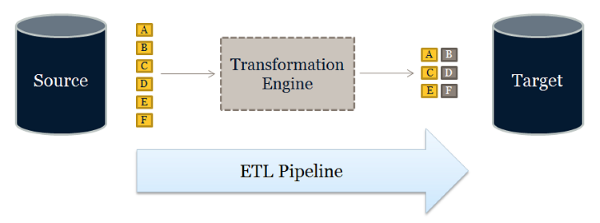
ETL is the most common way to move data around these layers, but there is also a variant of this approach, namely E-LT (or Extract, Load and Transform).This technique is a database centric method that is highly efficient and scalable. This method has several advantages over ETL such as utilizing the parallel processing features of the database to perform transformation, usually relying heavily on the in-house skills already available for maintaining the target repository.
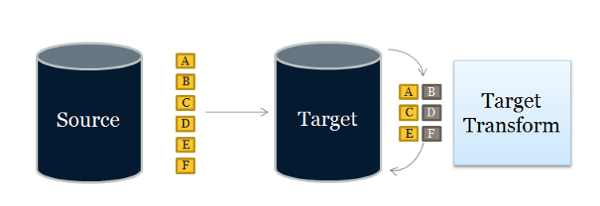
Which of the two methods is better, depends on priorities. As a general rule, it’s better to have fewer components in a data movement architecture. ELT has no transformation engine, since the work is done by the target system, which is already there, thus quite possibly reducing the need for additional resources and licenses.. Typically ELT is better when the target database is a high-end data engine, such as a Hadoop cluster. However, the ETL approach does have a reduced impact on the performance of the target system.
Both ETL and ELT are physical data movement capabilities. However, if both source and target repository reside on the same database server, logical data movement such as partition exchanges and materialized (or indexed) views also become viable tactical tools for these architectures.
The data movement capabilities already mentioned can all be place under the heading of bulk data movement. Another group of techniques we can group under incremental data movement, such as data replication typically employed in the creation and maintenance of one or more synchronized repositories, usually with the purpose of safeguarding from failures, corruptions, and performance issues. This capability is the lynchpin in addressing High Availability and Disaster Recovery requirements.
All of these methods are usually encapsulated within the Data Ingestion Services and Data Quality Services (which is the next topic to consider), as mentioned in a previous thought.
| Thought | EIM |