Structuring Data Entities12th of April 2018A central capability with Authoritative Data Management is the Canonical (or Common) Data Model. This model consists of all relevant business entities independent of the source repositories, and defines the often complex relationships between these entities. Either done at the project level or the enterprise level, this modeling is usually done by utilizing the Entity Relationship Diagram (ERD). Some other diagrams such as the Class Diagram from the UML standard or the IDEF1x from the IDEF family could be used as well, but ERD is by far the most common. Dan Brown, founder of EightShapes, wrote an article in 2010 titled “Eight Principles of Information Architecture”, in which he put forward his take on such an architecture. His focus with this particular article was mainly on Enterprise Content Management and how to present information to the consumer in need of this information. More specifically how to design a content delivery system such as a website or an intranet setup. But there are nuggets of wisdom in this list that can be applied to the data modeling in general. |
 |
The principles set out by Dan Brown are as follows:
| 1. Principle of Objects | Treat content as a living, breathing thing with a lifecycle, behaviors and attributes. Content has: a. A consistent a recognizable internal structure. b. A discrete set of behaviors. |
| → This is the same for information. Information is constantly changing and needs to be managed as such. | |
| 2. Principle of Choices | Create pages that offer meaningful choices to users, keeping the range of choices available focused on a particular task. |
| → This idea was pioneered in “The Paradox of Choice” by Barry Schwartz, and is too specific to the creation of web pages to translate to Authoritative Data Management. | |
| 3. Principle of Disclosure | Show only enough information to help people understand what kinds of information they’ll find as they dig deeper. |
| → No translating needed. Information presented to consumers that are not interested, is just noise. This is a sound principle for any form of data delivery capability. | |
| 4. Principle of Exemplars | Describe the contents of categories by showing examples of the contents. |
| → This concept can be applied to either Knowledge Management or Metadata Management, but not to the Authoritative Data Management discipline. | |
| 5. Principle of Front Doors | Assume at least half of the website’s visitors will come through some page other than the home page. |
| → Information can be accessed through various entry points. Make sure that your data modeling is consistent for any possible route taken. | |
| 6. Principle of Multiple Classifications | Offer users several different classification schemes to browse the site’s content. |
| → This concept can be applied to Metadata Management and Information Security Management. In a lesser capacity this could be applied to Authoritative Data Management for grouping data entities in business categories. | |
| 7. Principle of Focused Navigation | Don’t mix apples and oranges in your navigation scheme. Types of navigation: a. Topic Navigation b. Timely Navigation c. Signpost Navigation (list categories identifying the data) d. Marketing Navigation (long tail) |
| → Just like the Principle of Choices, this is too specific to the creation of web pages. | |
| 8. Principle of Growth | Assume the content you have today is a small fraction of the content you will have tomorrow. |
| → Always keep scalability of your models and architectures in mind when designing a solution. | |
As mentioned in an earlier thought, the four most enveloping characteristics of data are Volume, Variety, Velocity and Veracity. Volume deals with how much data is available to the organization, and what is the size of the interested datasets. Variety indicates the different types of formats and structures the data of an organization is structured in. Velocity is the rate at which data is dispersed across the different systems of the organization, but also the rate at which data changes. Veracity is the level of accuracy, consistency and completeness of the data available.

The Four V's of Big Data
Based on the Velocity characteristic for data movement, we can discern two types of data: Slow and Fast. Slow Data is most times referred to as Big Data, but I am not a fan of this denomination, as it would seem to suggest that Fast Data can’t be Big. Slow Data is essentially data at rest, with the potential to reach massive volumes. Fast Data is data in motion. This makes it fundamentally different from the data organizations typically think about. It requires a different approach and different technologies to deal with it. These technologies need to be able to analyze, decide and act on these data flows in real-time or at least with very low latency. Concepts associated with this type of processing are event stream processing and in-memory databases.
When dealing with event stream processing, I like the categorization of IBM for event types into three categories based in their nature: Business Events (relevant information for processing. For example “Customer Created”), operational events (information about system resources. For example “CPU Use at 80%”), and administration events (information about configuration changes. For example ”New Security Group Added”). Oracle approaches event types based on their significance and volume:
| Event Type | Description | Examples |
|---|---|---|
| Ordinary Events | Common non-critical events that are typically generated intermittently. | Information alerts, non-critical business events |
| Notable Events | Events that are important and need to be acted upon. These events typically occur at low volume. | Flight take off, customer service request, new application submission |
| Stream Events | Continuous stream of events that may not be significant | Stock quotes, RFID scans, heartbeats |
| Transactional Events | Important events generated through business transactions. These could be high volume events but may not necessarily have a correlating pattern. | Retail sales events, stock trades, flight ticket bookings |
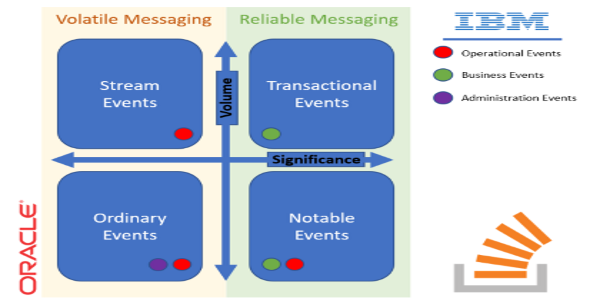
Different Event Types
In order to reduce the operational costs of maintaining data repositories, it is a good idea to attempt to limit or even reduce the variety of the organization’s data. Oracle proposes a number of Authoritative Data Management patterns to create a single version of the truth, which can be employed to this end. These patterns create a form of consolidation of all data within the organization, either by creating a centralized representation of the data or a consolidation (or some hybrid combination of both). They play for these patterns with the systems of entry (SOE), where the data gets put into a data repository and the system guaranteeing the data quality (DQ) by aggregation and consistency verification. These DQ systems could conceivably also be used to serve as Operational Data Stores.
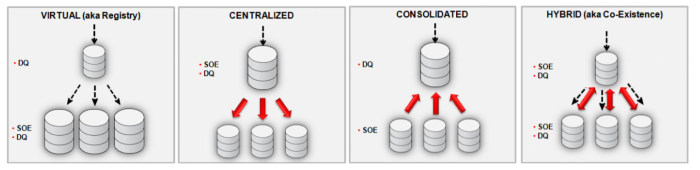
Authoritative Data Management Patterns (Oracle)
These patterns can be achieved by setting up ETL processes that facilitate these structures. The single version of the truth can then be achieved for master data as well as historical data, with these patterns resurfacing in the data structure design for the Data Warehouse Layer (also known as Foundation Layer in some methodologies). As the Data Warehouse Layer takes on the historical aspect of the data, this is more often than not different from the design for the Master Data.
| Thought | EIM |