Elementary, Dear Data
20th of February 2016|
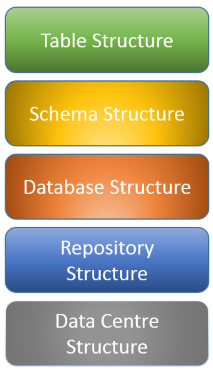
With a quick wink to the Star Trek series that commanded a significant part of my viewing experience during my adolescence, I proceed with my EIM series. Now that I have the conceptual stuff under my belt, it is time to assess how to logically structure an architecture for Enterprise Information Management. As specified in my white paper on Solution Architecture, the Logical View describes a decomposition of the solution into logical layers, subsystems and components of the system. This also includes the internal subsystems, components and the relations between them, but also the dependencies to the external systems and components. These logical components are closely tied to the business capabilities expected to be filled by an EIM solution. The information lifecycle shows the lynchpin concept be the management of information. Where does the information come from, where and how is it stored, how long and in which conditions do we keep information (preservation), and how do we deliver it to our consumers. All concepts of redundancy aside, it makes sense to determine which component (or repository) of our architecture will be considered the master of a certain type of information. Each of the main drivers for information lifecycles can be seen on different logical levels, as shown in the illustration to the right. The higher the level, the more granular it becomes. The least granular level is that of the data centre structure. It should capture in large blocks where information has its origin. The relationship between the data centres, both of the organization and of the partners it interacts with, can already indicate the master. For example, importing stock market streams into the organizational data can be useful, but normally it is data the organization will not be the owner of (unless you are the NYST or a similar organization). The modeling of these data centres should indicate which repositories are available and can also indicate the outer boundaries for certain types of information (delivery). An example would be privacy, where certain data should not leave sovereign soil to insure it cannot be forced into the open through judicial actions outside the sphere of influence of the laws governing it. For example, privacy data of civilians being protected under Belgian law would be accessible through the Patriot Act of the United States, should they reside on servers on American soil. |
|
The next level of modeling is the Repository Structure. At this level, the different types of stores discussed in the previous article get fleshed out. The model should not only determine purpose (live database, archive, reporting, failover …), but also indicate clusters or other constructs that cover any requirements for the information. In the physical view of a solution architecture, this gets linked to technical specifications such a s storage type and available communication channels (ODBC, TCP, web services…). For each repository, a listing of all databases needs to be included.
A Database Structure is in for example Oracle speak is the collection of all schemas logically grouped together with a number of management object impacting but not included in the schemas. This includes such configurations as tablespace and index space sizing, buffer pools, connection pools and the like. All of these additional objects are used to cover non-functional requirements, and can be mentioned as such in the solution architecture models, but are typically fleshed out as part of a more detailed technical design. In a fashion similar to the previous levels, this model should include a listing of all schemas associated with it.
The level of the schema structure contains the listing of all business entities contained within it. This is a logical representation (by means of for example the UML class diagram or a logical Entity Relationship Diagram). All business relevant entities are mapping to a table or combination of tables in preparation of the next level: the table structure, which is a level of detail seldom seen in solution architecture. Just as the modeling of the database structure, this level is mostly part of the technical design. The schemas should however indicates the type of persistence on which they operate (Relational, NoSql, Star/Snowflake/Constellation Schemas, …).
However, these 5 levels only cover the data at rest. Additionally, the data in motion should be modeled as well. This translates to data flow between each of the elements in the previous paragraphs, and is comparable to how services are modeling in a Service Oriented Architecture. With these flows, we chart the channels to be used by the producers and consumers of information within our organization, as well as beyond its architectural borders. These data flows can be very technical in nature, such as replication flows from a live repository to a failover repository, but can also have transformational qualities, adapted the data in transit to suit the needs of the receiving repository, such as for example Microsoft SQL Server Integration Services. These flows are divided into information services on the one hand, and provisioning services on the other.
Information Services are used to present information to consumers in a consumer-friendly manner via a clearly defined interface, creating an abstraction between the consumers and the actual sources of the information. There are several flavors of information services:
- Data Services: The main objective of data services is to provide aggregated, real-time, operational or historical data. They are supported by a canonical business information model, dispersed over one or more repositories, and with the aim of presenting a clear contextual and semantic view of the data independent of the repositories it is contained in.
- Content Services: These services expose search and discovery functionalities such as a free text or metadata searches, even when containing in artifacts stored in a repository (such as a PDF in a document server). Optionally they may even expose notification functionality to which consumers can subscribe.
- Analytical Query Services: These services are an extension to the standard data services. They expose analytical functionalities, and as such are aware of dimensional constructs (for example hierarchies or aggregations).
Provisioning services take the focus facilitating the providing of information. They are in effect highly optimized components for the provisioning and distribution of data. Just as information services, they provide a level of abstraction to shield the producers of data from the repositories where such data will be stored. Of these services, there exist the following flavors:
- Data Ingestion Services: These services enable data movement and processing capabilities to distribute and replicate volumes of data.
- Analytical Services: Service that enable analytical capabilities such as the programmatic approach for analysis execution (for example adaptions dimensions).
- Data Quality Services: Services that provide capabilities for maintaining data quality such as archiving and purging of large data repositories. This can be both batch and real-time, or even in a preventive manner.
- Repository Services: These services expose capabilities offered by the underlying repositories such as notification exposure or workflow management.
This cadence of Capturing, Storing and Providing information is a separation of concerns in order to ensure that the consumers of information are shielded from the possible complexity and heterogeneous locations of said information. It also provides an organization with the flexibility to change underlying structures at all levels without impacting its consumers. The next step in fleshing out Enterprise Information Management is to examine the different ways we can leverage the information available to maximize the knowledge and wisdom within the organization. In other words, the Management part of our lifecycle. For this, we examine the different sub-disciplines of EIM in the next article.
| Thought | EIM |