All Roads Lead to Information...
14th of July 2016The discipline of Enterprise Information Management (EIM) is made up of a set of business processes, practices and subdisciplines that are leveraged to manage all data (from unstructured to strategic) in order to transform them into enterprise assets. It needs to ensure that these assets are high quality, available, protected and effectively leveraged to meet the needs of all enterprise stakeholders and that they support the strategic vision of the enterprise. It represents a framework of different disciplines, spanning all departments within the enterprise. This is not a topic to be left to a single stakeholder lest the overall efficiency of the enterprise be compromised. A graphical representation of these disciplines can be seen in the illustration below.
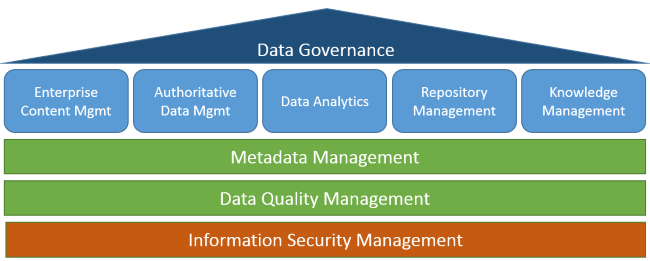
The different subdisciplines are Enterprise Content Management (ECM), Authoritative Data Management, Data Analytics, Repository Management and Knowledge Management. There are also three transversal disciplines which impact all these subdisciplines, namely Metadata Management, Data Quality Management and Information Security Management. All of these combined should be placed under the watchful eye of an office for data governance.
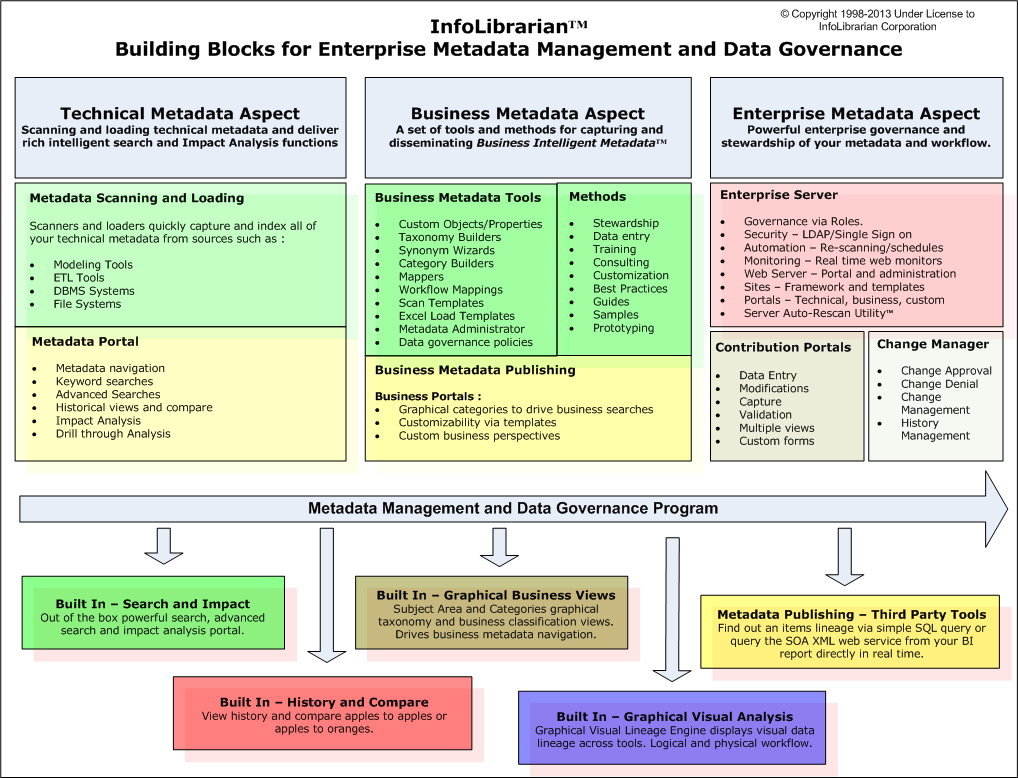
Metadata Management gives context to the data in terms of definition, control, usage and treatment of content within a system, application or organization. This is what we define as Business Metadata. Metadata Management forms the glue between the different subdisciplines, and promotes/assists in the use of the tools and techniques of each of these. It allows the addition of characteristics by the components of your environment such as access and usages metadata in order to support respectively Information Security and Data Quality Management. This type of metadata we label as Operational Metadata. Technical Metadata describes data structures and formats (table types, column types, indexes …) making versioning of these structures and configurations possible (to support Repository Management). Finally, there is Process Metadata stipulating the different rules and policies governing the data (such as data cleansing rules, transformation rules, validation rules, integration rules…). A similar approach can be seen on the website of the Infolibrarian Corporation.
Associated with Metadata Management are several capabilities to create such a context between data sets. The Introspection capability focuses on discovery and harvesting in order to determine the population of the metadata repository with objects, attributes, relationships, configuration details… These metadata sets can not only be used as a source of context, but are leveraged in another capability: Impact Analysis. This capability is about seeing dependencies across the architecture in order to predict the effects of a change. Another use for metadata is the tracking of the origin of data through the architecture: How it entered into the datasets of an organization, by which means… This is called the Data Lineage.
Data Quality Management entails defining quality metrics, analyzing and profiling data quality, and even certifying and auditing said quality (based on service levels). Based on these metrics, and following rules laid out in the metadata, steps are taken to validate and achieve quality requirements (such as the proactive or reactive cleansing of data). This subdiscipline has already received some attention in a previous thought.
Information Security Management deals with the sensitivity of data (such as control or privacy) by establishing, implementing, administering, and auditing policies, rules and procedures within an enterprise. This is also the domain of one of the more known ISO certifications an enterprise can attain, namely the ISO 27001 certification, titled “Information Security Management”.
Authoritative Data Management deals with the information lifecycle (Capture/Store/Preserve/Deliver) of the business entities. It also regulates which business entities are to be read or adapted (CRUD) by which consumers, based on the policies laid out in the Information Security Management discipline. It divides these tasks over distinct subdisciplines:
- Master Data Management: Provides the single version of the truth for live data (also called transaction data).
- Historical Data Management: Discipline responsible for the lifecycle of data needed for analysis, integration, consolidation, and strategic decision making. This is typically in an application- and business neutral form.
- Retention Management: Regulates the ageing of data and the determination of its relevance based on its age, company policies and regulations (or litigations). This includes discovery of belated data as well as its archiving, and eventual elimination.
A central capability with Authoritative Data Management is the Canonical (or Common) Data Model. This model consists of all relevant business entities independent of the source repositories, and defines the often complex relationships between these entities. This forms the basis for another capability: entity consolidation. In order to reduce fragmentation and duplication across operational systems, efforts can be taken to restructure these repositories. The capability also provides the data cleansing efforts with needed information to perform their activities. A capability specific to retention is data freezing, where data is put in a status making it exempt from archiving/elimination strategies.
Where Historical Data Management deals with the storage and Retention Management deals with latency and archiving, the Data Analytics discipline will take the data available and provides interpretation of this data. It does this in four stages, which are described in a previous thought.
Where Authoritative Data Management deals with structured data, Enterprise Content Management (ECM) deals with unstructured data. This is covered by subdisciplines based on the type of unstructured data they handle: Document Management (and its associated document lifecycle processes), Digital Asset Management (and subsequent branding content fit for all media), Web Content Management (handling the online presence of the organization), and Imaging Management (dealing with the digitalization of paper information).
Repository Management deals with the management of the physical data resources (environments, configurations, test data sets, migration…) , as well as the services that monitor the lifecycle of information from an operational perspective: external data acquisition, backup & recovery, performance monitoring, …
Knowledge Management (KM) is the leveraging of collective wisdom to increase responsiveness and innovation (as defined per the Delphi Group). It is the systematic, explicit and deliberate
building, renewing and applying of knowledge to maximize an organization’s effectiveness (sustainable competitive advantage, sustainable high performance…) and returns derived from its
knowledge assets. Plain and simple, Knowledge Management is about getting the right knowledge to the right people at the right time. This is captured in the following quote:
- Thomas Davenport and Lawrence Prusak
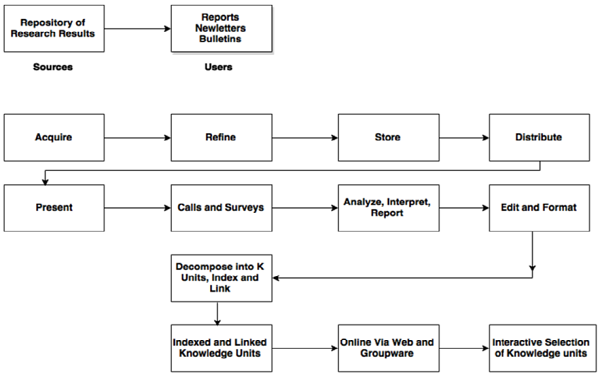
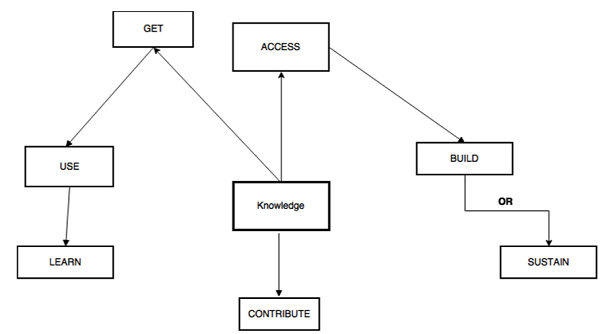
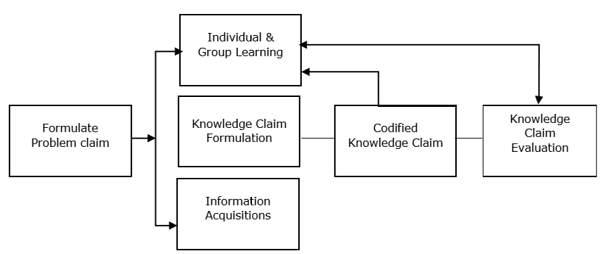
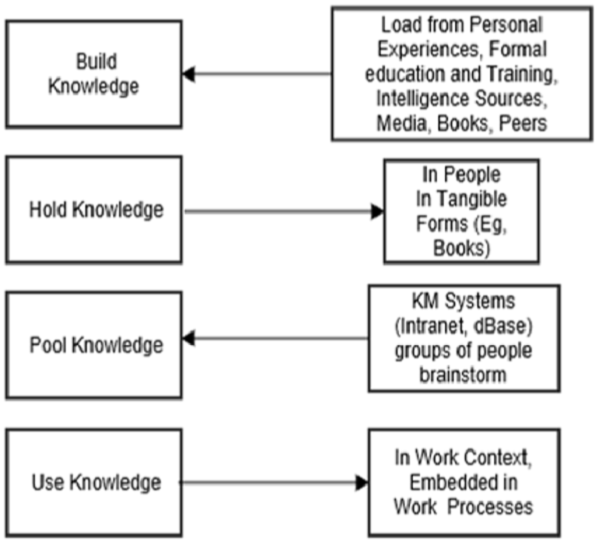
All literature on the subject indicates that the Knowledge Management discipline is a continuous cycle. There are several models for this cycle that are widely accepted. The four models are the Zack, from Meyer and Zack (1996), the Bukowitz and Williams (2000), the McElroy (2003), and the WIIG (1993) KM cycles. Their essence can be captured by using an Integrated KM Cycle as proposed by Kimiz Dalkir in his 2005 book “Knowledge Management in Theory and Practice”, and as shown in the illustration below.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
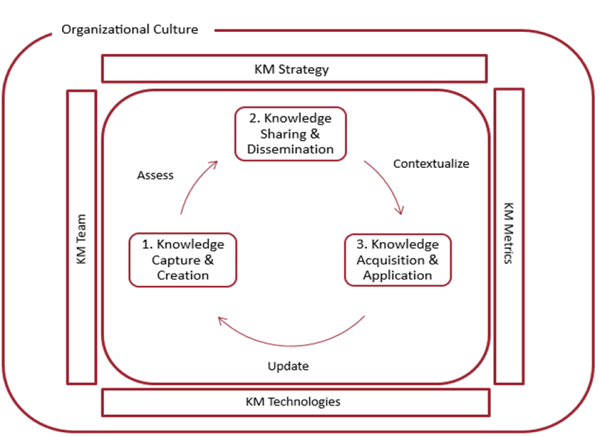
Since the discipline of Knowledge Management is such an important topic, I will delve a bit more into detail on it in a future thought.
| Thought | EIM |